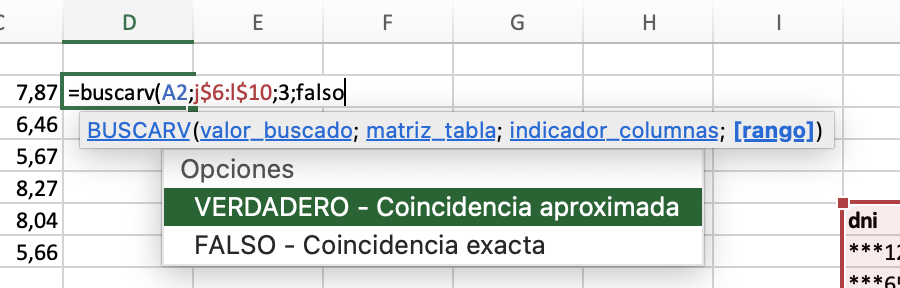
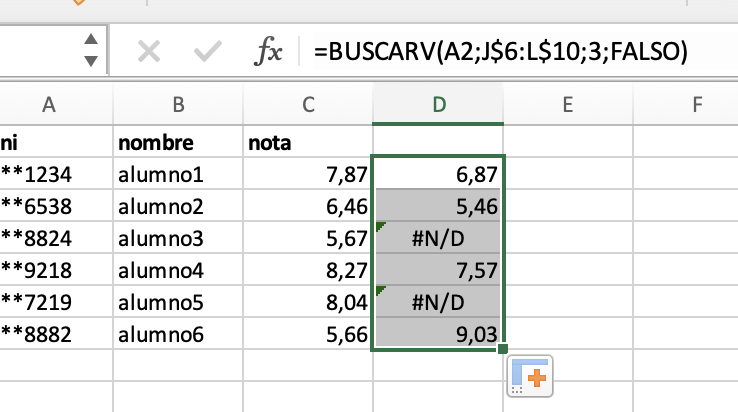
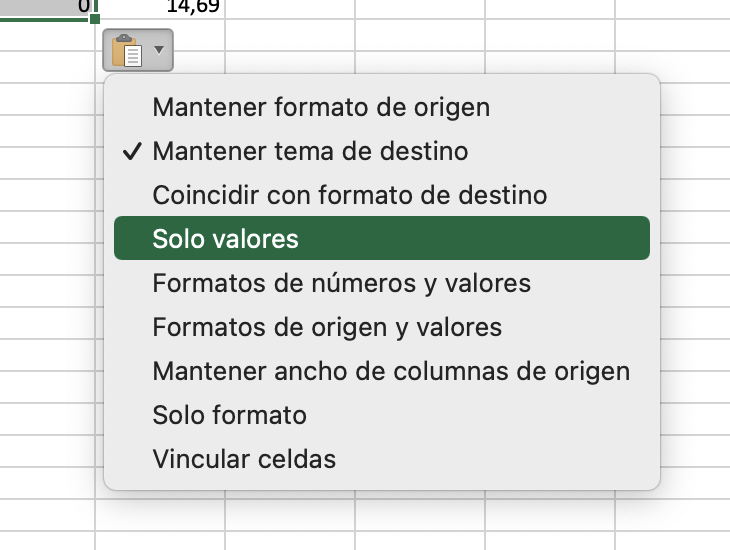
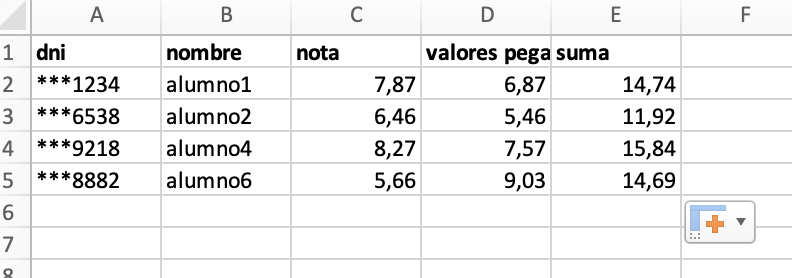
si tenemos un directorio que contiene imágenes y queremos reducir su tamaño, podemos utilizar un script desde un cron que recorre todas las imágenes, comprueba su tamaño y si es mayor del esperado lo reduce a la mitad
<?php
function createthumb($name,$filename,$new_w,$new_h){
$system=explode('.',$name);
$numparam=count($system);
$tipo="";
if (preg_match('/jpg|jpeg/',$system[$numparam-1])){
$src_img=imagecreatefromjpeg($name);
$tipo="jpg";
}
if (preg_match('/png/',$system[$numparam-1])){
$src_img=imagecreatefrompng($name);
$tipo="png";
}
if ($tipo!=""){
$old_x=imageSX($src_img);
$old_y=imageSY($src_img);
if ($old_x > $old_y) {
$thumb_w=$new_w;
$thumb_h=$old_y*($new_h/$old_x);
}
if ($old_x < $old_y) {
$thumb_w=$old_x*($new_w/$old_y);
$thumb_h=$new_h;
}
if ($old_x == $old_y) {
$thumb_w=$new_w;
$thumb_h=$new_h;
}
$dst_img=ImageCreateTrueColor($thumb_w,$thumb_h);
if ($tipo=="png")
{
imagealphablending($dst_img, false);
imagesavealpha($dst_img, true);
imagecopyresampled($dst_img,$src_img,0,0,0,0,$thumb_w,$thumb_h,$old_x,$old_y);
imagepng($dst_img,$filename);
} else {
imagecopyresampled($dst_img,$src_img,0,0,0,0,$thumb_w,$thumb_h,$old_x,$old_y);
imagejpeg($dst_img,$filename);
}
imagedestroy($dst_img);
imagedestroy($src_img);
return $filename;
}else{
return null;
}
}
$directorio = '.';
$ficheros1 = scandir($directorio);
$imagenes=0;
$contador=0;
foreach ($ficheros1 as $key => $value){
if (!in_array($value,array(".",".."))){
if (is_dir($directorio . DIRECTORY_SEPARATOR . $value)){
//no hacer nada
}else{
$imagenes++;
$gis=@getimagesize($value);
list($width, $height, $type, $attr) = $gis;
if ($width>=1000 || $height>=1000){
print_r($value);
echo " ".$width."x".$height;
echo " hay que redimensionar";
$filename="".$value;
$new_w=(int)($width/2);
$new_h=(int)($height/2);
createthumb($value,$filename,$new_w,$new_h);
$contador++;
echo "
";
}
// esto solo si hay problemas de timeout
//if ($contador==500){break;}
}
}
}
echo "Se han convertido $contador de $imagenes imagenes";
?>
Se podria mejorar buscando imagenes en lugar de recorrer todos los archivos, pero queda para otro momento